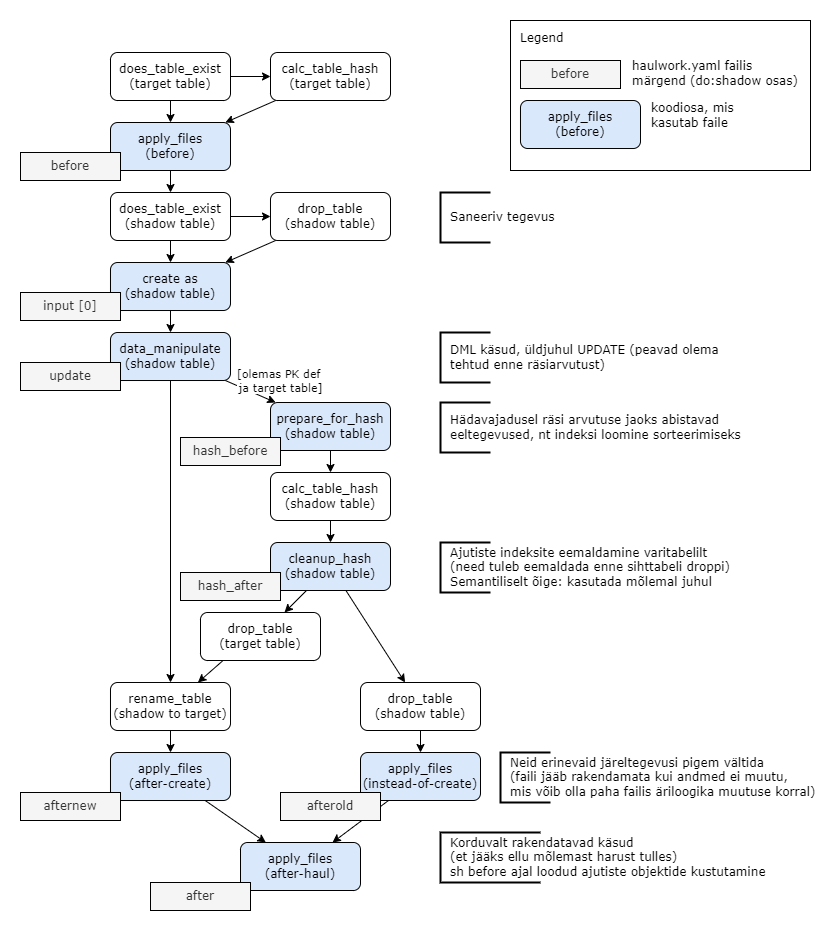
Agent: shadow
Replaces deprecated "map" aka "view".
Creates new table as shadow table, compares with existing one and switches if different
Syntax and samples
- do: shadow
before: before.sql # if needed create temporary tables, fullfil them and create indices
input: input.sql # select to use *inside* create table ... as ( ... ) command between parentheses
update: update.sql # data manipulation after input and before calculating hashes
hash_before: hash_before.sql # help actions to speed up hash calculation (eg. create index)
hash_after: hash_after.sql # undo before actions to keep thing clean (eg. drop index)
afternew: afternew.sql # actions only if table was created (try to avoid)
afterold: afterold.sql # action only if table already existed (try to avoid)
after: after.sql # common last actions (indeces, comments), keep them re-applyable!!!
pkcol: # columns names for calculating hash (think them as they are primary key columns)
- address_id
Tags for files can be string or array of strings. In case of array files will be applied in defined order.
Exception: for input-part only first file is used (if multiple defined).
Warning
input.sql cannot contain semicolons (outside of strings)
-- Minimal sample
-- input.sql (no semicolon!) NB! year is pkcol (primary key column for target table)
SELECT year, sum(money) as yearly_income FROM my_schema.my_table GROUP BY year
-- More fun sample
-- input.sql (no semicolon!) NB! year is pkcol
SELECT year, sum(money) as yearly_income, null::boolean as good_year
FROM my_schema.my_table GROUP BY year
-- update.sql
UPDATE {{target_schema}}.{{target_table}}
SET good_year = true
WHERE yearly_income > (SELECT avg(yearly_income) FROM {{target_schema}}.{{target_table}});
UPDATE {{target_schema}}.{{target_table}}
SET good_year = false
WHERE good_year IS NULL;
-- hash_before.sql
CREATE INDEX ixt_{{target_schema}}_hash ON {{target_schema}}.{{target_table}} (year);
-- hash_after.sql
DROP IF EXISTS INDEX {{target_schema}}.ixt_{{target_schema}}_hash;
-- afternew.sql ("if not exists" is not needed, because view is already dropped before this moment)
CREATE VIEW IF NOT EXISTS {{target_schema}}.vw_{{target_table}}_last_5 AS (... ... LIMIT 5);
Remarks
- use hash_before only if really needed (table is huge)
- if use hash_before add companion/reverse hash_after
- if hash_before makes universally good index, anyway drop it in hash_after and create again in after (use different name)
- if use before to create temp tables use after to drop them (they will drop itselves due DB session management, but so it will be more clear)
- if you need some database units which are tied with target table (eg Postgre function what uses table name for type declaration) they are droped only if table is replaced by shadow and so they must be recreated in afternew
- SQL in after must be re-applyable (cannot depend on table existence earlyer)
Workflow
Diagram below (png-picture, in Estonian) may help little bit to understand